Van Eck's Sequence
Van Eck’s sequence (A181391) is a recursively defined sequence which has some interestingly complicated behavior. I heard about it in the Numberphile video Don’t Know.
The first term is 0. Here’s the rule to get the next term: Look at the previous term. If you’ve seen that number before in the sequence, then this term is how far back you last saw it. If the previous term has never occurred before, then this term is a 0.
The first few terms are 0, 0, 1, 0, 2, 0, 2, 2, 1, 6, 0, 5, ...
Here’s how the first few steps go:
- To get the second term we look back at the first term, which is 0. 0 has never occurred before (since we just started), so the second term is also 0.
- To get the third term, look back at the previous 0. Now we have seen a 0 before, just one more step back, so the third term is 1.
- 1 is new, so the fourth term is 0.
- We have seen a zero before, two steps, back, so the fifth term is 2.
- And so on…
More precisely (quoting the OEIS definition):
For n >= 1, if there exists an m < n such that a(m) = a(n), take the
largest such m and set a(n+1) = n-m; otherwise a(n+1) = 0. Start with
a(1)=0.
It’s been proven that there are an infinite number of 0s – which means there are always new numbers which have never occurred before – but many other questions remain unanswered, such as whether every number will eventually occur. (See A181391 for lots more information and references.)
Computation
To compute Van Eck’s sequence, we have to remember the last position at which we saw each unique value which has occurred in the sequence. A few observations:
- In general it seems that new values occur about every log10(n) terms. So if we want to compute, say, 1012 terms, we’ll need storage for about 1012 / 12 values and the most recent position in the sequence where they occurred.
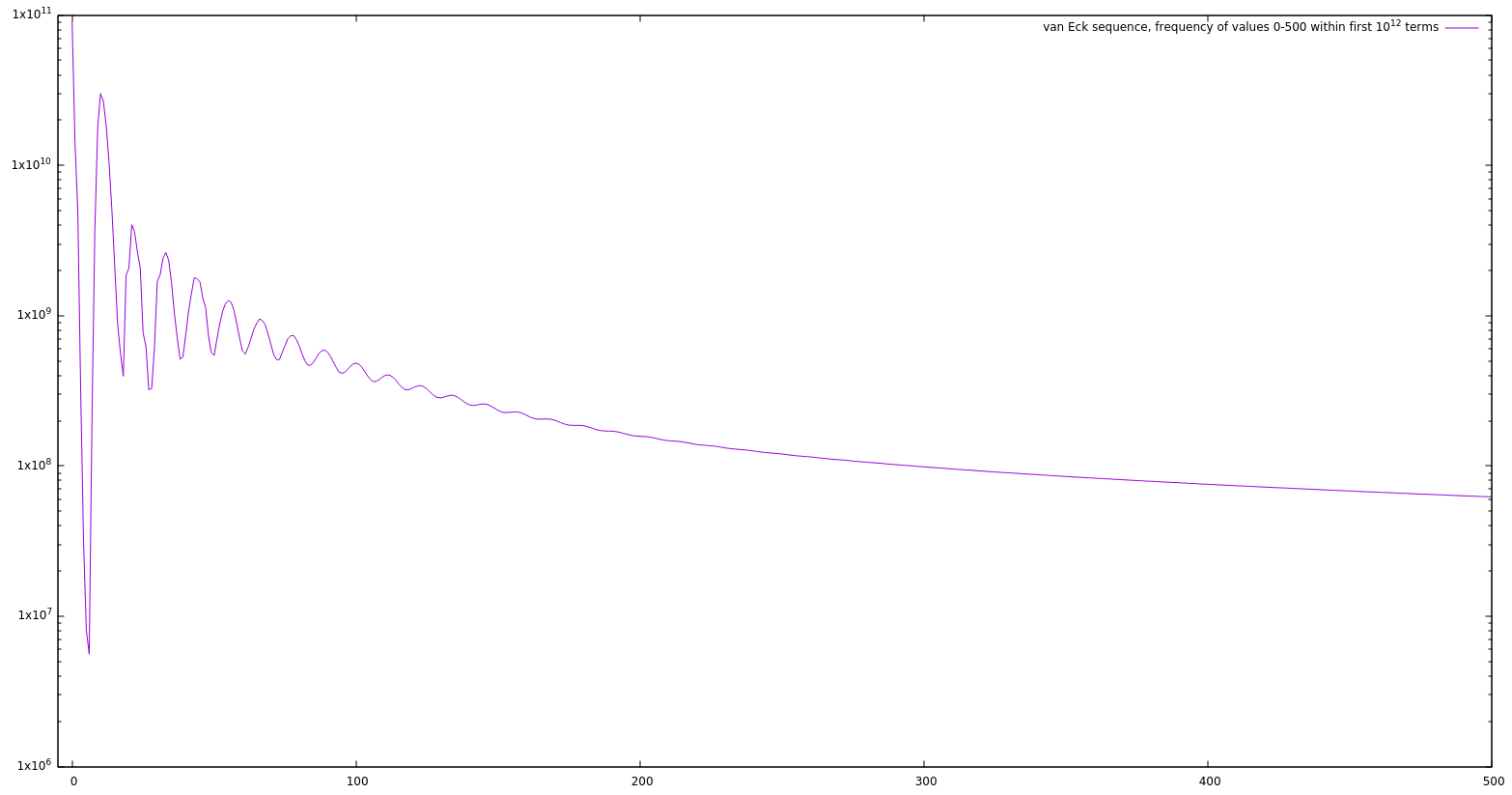
- Values are not evenly distributed – smaller numbers are more common, with the frequency of larger values falling off smoothly.
- It’s easy to see that the Nth term of the sequence must be less than N, so the number of terms we aim to compute is also a bound on the size of the values we need to store.
For small values, a simple lookup table which contains the last position at which each value occurred is fast and space-efficient, because small values are common and so most table entries are used. Larger values are sparser; there are more numbers which have never occurred in the sequence, which would mean unused table entries, and so a hash table becomes more efficient, even though its entries take (initially) twice as much space since they have to store both the position and the value.
We can quickly save some space by using only as many bytes as necessary for our data. 1012 is a little less than 240, so we can get to a trillion terms using 40-bit (5-byte) numbers. The C bitfield syntax gives a convenient way to do this:
typedef struct {
unsigned long position : 40;
} __attribute__ ((packed)) table_entry_t;Normally the compiler would pad this struct out to 8 bytes to keep
memory accesses nicely aligned, but the packed attribute says to
squish them all together. With a modern processor and compiler, the
performance impact is minimal, and well worth saving 37.5% of our
memory.
Likewise, the hash table entry contains two 5-byte integers, for the value and its last position. With some experimentation we can estimate a good cutoff for when we switch from the lookup table to the hash – when the values of the sequence become sparse enough that the lookup table is less than half utilized.
Some hardware considerations
If you look at sequence, the successive terms have a sort of “Christmas tree” shape: a 0 is followed by (usually) successively larger values until there’s a really big one which has never been seen before, which means the following term is back to 0.
But from the point of view of the processor, they might as well be random. And since each term is looked up in a giant array or hash to get the next term, that means a big series of data-dependent random memory accesses, which is pretty much the worst possible case for memory performance. The program’s time is going to be dominated by cache miss and TLB miss (page table walk) latency.
There’s not a whole lot we can do about this, but we can help a bit:
- In the hash table, collisions are handled by just scanning linearly for the next available spot. This isn’t always the best policy – rehashing to somewhere far away can help avoid pileups and keep things evenly distributed throughout the table – but it’s good here because rehashing would probably generate another page miss, and we can scan a lot of entries in the time that would take.
- Enabling transparent huge pages (THP) on Linux with
sudo hugeadm --thp-alwayswas worth about a 30% performance improvement. Using 2MB pages instead of 4KB pages will improve TLB hit rates somewhat, but more importantly it shortens the page walk by one level, and makes the page tables themselves much smaller so that they don’t compete so much for cache space with the actual data. - As soon as we have a term, doing a software prefetch using gcc’s
__builtin_prefetch()is worth a few more percent. That gets the next miss started while we do various statistics and bookkeeping on the current term.
A better hash table
The hash table stores the value as well as the position, so we can tell whether the entry we’ve found is actually the value we’re looking for. But if we’re careful about the choice of hash function, we can know a lot about the value based on where it sits in the hash table.
For instance, say we have a hash table with 232 entries. If
our hash function is just value % (1<<32), then the index into the
hash table gives us the low 32 bits of the value, and we only need to
store the upper 8 bits.
Of course that only works until you have a collision. Once you put something in a different location than it originally hashed to, you’ve lost the information about what the original value is. We can fix this by also storing a small offset, which records how far away this value is from its desired location in the hash.
For this sequence, a simple mod doesn’t work well as a hash function because smaller values are more common, so the low end of the hash table fills up first. To fix that without losing any information about the value, we can rotate it by a few bits before modding by the hash size.
Finally, the size of the offset means that there’s a limit on how many collisions we can have in a row when inserting a value. To get around this, if we reach the collision limit (2offset_size occupied entries in a row) then we fall back on a small secondary hash table which stores the full value and position.
The size of the hash table determines how many bits of the value you can extract from the hash index, and thus how many upper bits have to be stored in the hash entry. With a hash table of over 236 entries, we can use this structure:
typedef struct {
unsigned long position : 40;
unsigned long upper_value : 4;
unsigned long offset : 12;
} __attribute__ ((packed)) hash_entry_t;This is only 7 bytes – a significant improvement over the 10 bytes we started with.
Results
My home machine has 128GB of memory, with which I was able to reach about 210 billion terms, storing 19.7 billion value/position pairs. But I really wanted to reach 1 trillion, so I ventured into Google Cloud for the first time.
The ‘ultramem’ class of machines offers really large memory sizes, up to 3.8TB. Allowing your job to be pre-empted reduces the price by about 80%, but you could get kicked off any time, and there’s a 24-hour maximum.
So I gambled… and won! Using a machine with 960GB of memory, I made it the full 24 hours without getting bumped, and hit the 1 trillion mark with just 6 minutes to spare.
After 10^12 terms, there have been 90689534032 zeros (which equate to unique values), and the smallest number not appearing is 1732029957. And I got some nice graphs of the long-term behavior:
- Frequency of values 0..500 over the first 10^12 terms
- Frequency of values 0..1000000 over the first 10^12 terms
- Average distance between 0s over the first 10^12 terms
{kind=link}
{kind=link}
{kind=link}
Overall the computation didn’t really produce any surprising results, but it was a lot of fun, and the space-saving hash table technique and knowing how to rent a cloud machine will surely be useful again.